Python注册登录时验证码识别处理方法实例
Python验证码识别处理方法实例
对于爬虫来说,一个比较大的阻碍就是验证码,验证码也是反爬虫的有效措施之一。接下来针对验证码出现的方式,就如何突破验证码进行进一步的探讨。
10.2.1 IP代理
当你使用同一个IP频繁访问网页时,这时候网站服务器就极有可能将你判定为爬虫,此时会在网页中出现验证码,输入正确才能正常访问,类似淘宝的这种情况,如图10-20所示。
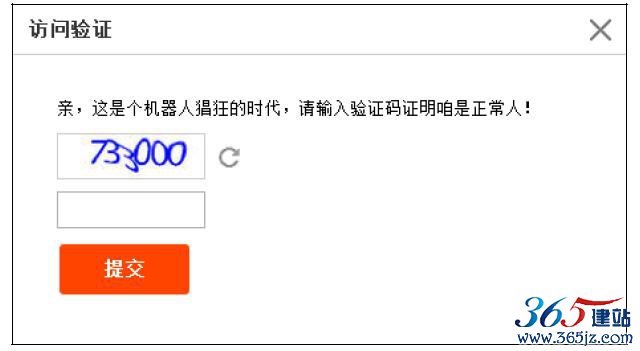
图10-20 访问验证
这种验证码的产生原因是由于同一IP的频繁访问,当然你可以加大爬虫的延时,做到和人访问速率一样,不过这样效率稍微低一些,好的做法是换IP进行访问。
之前对于urllib2和Requests如何配置代理IP的方法已经进行了讲解,这里不再进行赘述。大家可能更关心的是如何获取更多的代理IP,主要有以下几种方式:
·首先是VPN:国内和国外很多厂商提供VPN服务,可以分配不同的网络线路,并可以自动更换IP,实时性很高,速度很快。稳定可靠的VPN的价格一般都不低,适合商用。
·IP代理池:一些厂商将很多IP做成代理池,提供API接口,允许用户使用程序调用。稳定的IP代理池也是很贵的,不适合个人学习使用。
·ADSL宽带拨号:大家肯定都用过拨号上网的方式,ADSL有个特点是断开再重新连接时分配的IP会变化,爬虫可以利用这个原理更换IP。由于更换IP需要断开再重连,使用这种方式的效率并不高,适合实时性不高的场景。
VPN和IP代理池都有厂商各自提供的更换IP接口,大家可以根据自己选择的厂商进行配置。
ADSL宽带拨号,可以使用Python实现拨号和断开,比如Windows提供了一个用于操作拨号的命令rasdial,接下来用Python操作这个命令实现上网,代码如下:
# coding:utf-8 import os
import time
g_adsl_account = {"name": "adsl", "username": "xxxxxxx", "password": "xxxxxxx"} class Adsl(object):
##################################################### # __init__ : name: adsl名称##################################################### def __init__(self):
self.name = g_adsl_account["name"]self.username = g_adsl_account["username"] self.password = g_adsl_account["password"] ##################################################### # set_adsl : 修改adsl设置
##################################################### def set_adsl(self, account):
self.name = account["name"] self.username = account["username"] self.password = account["password"] ##################################################### # connect : 宽带拨号##################################################### def connect(self):
cmd_str = "rasdial %s %s %s" % (self.name, self.username, self.
password)
os.system(cmd_str)
time.sleep(5)
#################################################### # disconnect : 断开宽带连接################################################## def disconnect(self):
cmd_str = "rasdial %s /disconnect" % self.name
os.system(cmd_str)
time.sleep(5)
###################################################### reconnect : 重新进行拨号
##################################################### def reconnect(self):
self.disconnect()
self.connect()
if __name__=='__main__':
adsl = Adsl()
adsl.connect()
现在有很多提供宽带拨号的服务商,提供专门的VPS拨号主机,例如无极网络等,价格不是很贵,也相对比较稳定,大家可以尝试去用一下,IP基本上是秒切换。
最后提供一个适合个人使用的代理方式IPProxyPool,这是本人用Python写的一个开源项目,放置于GitHub:https://github.com/qiyeboy/IPProxyPool。原理:通过爬取各大IP代理网站的免费IP,将这些IP进行去重、检测代理有效性等操作,最后存储到SQLite数据库中,并提供一个API接口,方便大家调用。以Windows使用进行讲解:
1)使用git将代码clone到本地,或在GitHub上下载IPProxyPool压缩包解压即可
2)进入IPProxyPool目录,在命令行窗口运行Python IPProxys.py
这个时候IPProxyPool就开始工作,爬取免费IP了。每半个小时进行一次IP的爬取和校验,防止IP失效,效果如图10-21所示。
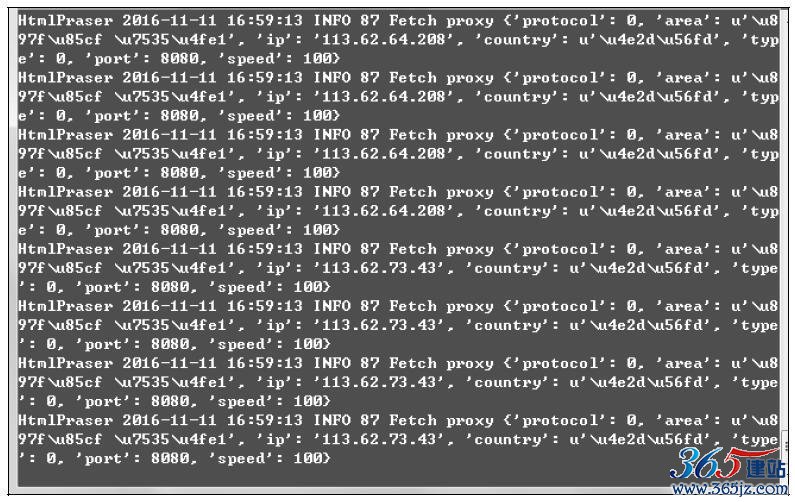
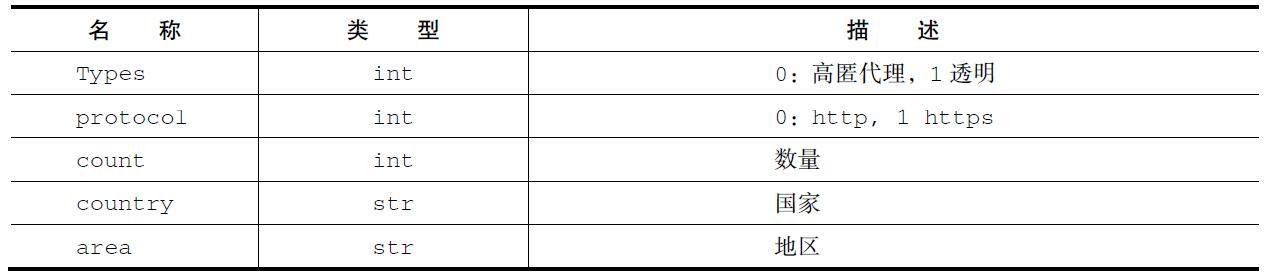
图10-21 IPProxys运行
那我们自己的爬虫如何获取IPProxyPool提供的IP呢?非常简单,IPProxyPool提供了一个HTTP请求接口,假如我们的爬虫程序和IPProxys在同一台主机上,可以向127.0.0.1:8000发送一个GET请求,请求参数如表10-3所示。
表10-3 GET参数
假如发送的GET请求为http://127.0.0.1:8000/
types=0&count=5&county=中国,这个请求的意思是返回5个IP所在地在中国,类型为高匿的IP地址,响应格式为JSON,按照响应速度由高到低,返回数据,类似[{“ip”:“220.160.22.115”,“port”:80},
{“ip”:“183.129.151.130”,“port”:80},{“ip”:“59.52.243.88”,“port”:80},{“ip”:“112.228.35.24”,“port”:8888},{“ip”:
“106.75.176.4”,“port”:80}],大家在爬虫程序中只要将响应进行解析即可。示例代码如下:
import requests
import json
r = requests.get('http://127.0.0.1:8000/types=0&count=5&country=中国')
ip_ports = json.loads(r.text)
print ip_ports
ip = ip_ports[0]['ip'] port = ip_ports[0]['port'] proxies={ 'http':'http://%s:%s'%(ip,port), 'https':'http://%s:%s'%(ip,port)
} r = requests.get('http://ip.chinaz.com/',proxies=proxies)
r.encoding='utf-8'
print r.text
根据我的统计,一般有用的代理IP在70个左右,完全满足个人的需要。
10.2.2 Cookie登录
当我们在登录的时候遇到了验证码,这时候我们需要人工识别之后才能登录上去,其实这是个非常繁琐的过程,每次登录都要我们手动输入验证码,很不可取。但是大部分的网站当你登录上去之后,
Cookie都会保持较长的一段时间,避免因用户频繁输入账号和密码造成的不便。我们可以利用这个特性,当我们登录成功一次之后,可以将Cookie信息保存到本地,下次登录时直接使用Cookie登录。以10.1
节的知乎登录为例,我们可以加入两个函数:save_session和load_session。代码如下:
def save_session(session):
# 将session写入文件: session.txt
with open('session.txt', 'wb') as f:
cPickle.dump(session.headers, f)
cPickle.dump(session.cookies.get_dict(), f)
print '[+] 将session写入文件: session.txt'
def load_session():
# 加载session
with open('session.txt', 'rb') as f:
headers = cPickle.load(f)
cookies = cPickle.load(f)
return headers,cookies
10.2.3 传统验证码识别
当我们识别并手动输入验证码,成功登录,并保存Cookie信息以便下次使用,这些操作做完之后仅仅可以暂时松一口气,因为Cooke总有失效的时候,下次还是要重复这个过程,尤其是爬取的网站很多时,将是一个很繁重的工作。如果能使用Python程序自动识别验证码,这将是一件省时省力的事情,这就涉及传统验证码的识别。
为什么限定为传统验证码呢?传统验证码即传统的输入型验证码,可以是数字、字母和汉字,这类验证码不涉及验证码含义的分析,仅仅识别验证码的内容,识别相对简单,进行验证码识别需要使用到tesseract-ocr。下面讲解一下Python如何使用tesseract-ocr进行验证码识别。
Python识别验证码需要安装tesseract-ocr、pytesseract和Pillow。
Ubuntu:
·tesseract-ocr:sudo apt-get install tesseract-ocr·pytesseract:sudo pip install pytesseract·Pillow:sudo pip install pillow
Windows:
·tesseract-ocr:下载链接为http://digi.bib.uni-mannheim.de/
tesseract/,下载后直接安装,建议使用安装过程中的默认选项,安装目录默认为C:\Program Files(x86)\Tesseract-OCR。

·pytesseract:pip install pytesseract·Pillow:pip install pillow
安装完成后开始进行识别验证码,以这个验证码为例,识别代码如下:
# coding:utf-8 import pytesseract
from PIL import Image
image = Image.open('code.png')
# 设置tesseract的安装路径pytesseract.tesseract_cmd = 'c:\\Program Files (x86)\\Tesseract-OCR\\
tesseract.exe'
code = pytesseract.image_to_string(image)
print code
输出结果为:
0376
我们只是简单介绍了tesseract-ocr的使用,对验证码的识别涉及图像处理方面的知识,提高识别率还要学习训练样本,本节不进行扩展讲解,感兴趣的话大家可以自行研究。
图10-22 注册界面
注册完成后,官方提供了各种编程语言接入方式的示例,其中就有Python的,如图10-23所示。
大家可以根据提供的API示例,开发自己的识别程序。
图10-23 Python示例
10.2.5 滑动验证码
滑动验证码是最近比较流行的验证方式,是一种基于行为的验证方式,如图10-24所示。
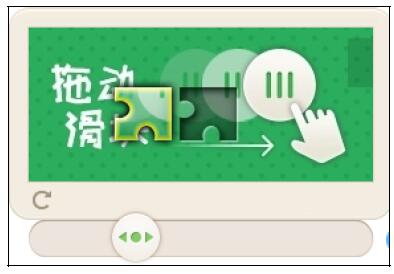
图10-24 滑动验证码
滑动验证码虽然验证方式比较特别,不过依然有办法突破,一种通用的办法是使用selenium来进行处理。主要的技术要点有:
·在浏览器上模拟鼠标拖动的操作。
·计算图片中缺口的偏移量。
·模拟人类拖动鼠标的轨迹。
由于涉及图像拼接方面的知识,此处不再深入讲解。如果遇到这种情况,大家可以采取多账号登录后,保存cookie信息,组建cookie池的方法绕过。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛

