python爬虫入门教程之 Selenium库的使用
python爬虫入门教程之 Selenium库的使用
上一节我们讲解了PhantomJS的用法,它只是一个没有界面的浏览器,运行的还是JavaScript脚本,这和Python爬虫开发有什么联系呢?本节介绍的Selenium能将Python和PhantomJS紧密地联系起来,从而实现爬虫的开发。
Selenium是一个自动化测试工具,支持各种浏览器,包括Chrome、Safari、Firefox等主流界面式浏览器,也包括PhantomJS等无界面浏览器,通俗来说Selenium支持浏览器驱动,可以对浏览器进行控制。而且Selenium支持多种语言开发,比如Java、C、Ruby,还有Python,因此Python+Selenium+PhantomJS的组合就诞生了。
PhantomJS负责渲染解析JavaScript,Selenium负责驱动浏览器和与Python对接,Python负责做后期处理,三者构成了一个完整的爬虫结构。
9.4.1 安装Selenium
Selenium现在最新的版本为3.0.1,本书也是以此为标准进行讲解。Selenium官方地址为:http://www.seleniumhq.org/,其安装主要有两种方式:
·pip install Selenium==3.0.1·从https://pypi.python.org/pypi/selenium下载源代码解压后,运行python setup.py install。
·Selenium3.x和Selenium2.x版本有以下区别:
·Selenium2.x调用高版本浏览器会出现不兼容问题,调用低版本浏览器正常。
·Selenium3.x调用浏览器必须下载一个类似补丁的文件,比如Firefox的为geckodriver,Chrome的为chromedriver。
各种版本浏览器的补丁下载地址为:http://www.seleniumhq.org/download/,如图9-11所示。
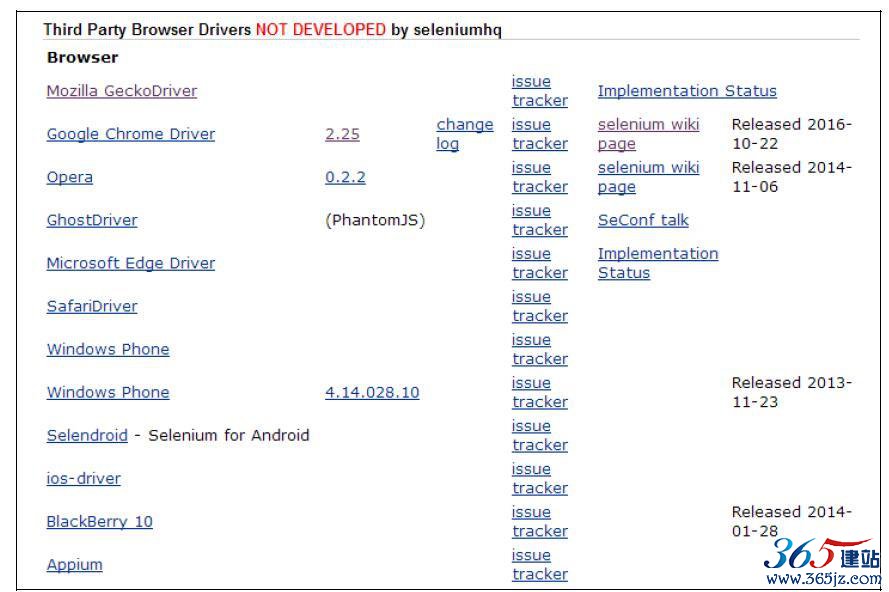
图9-11 补丁下载地址
根据自己的操作系统,下载指定的geckodriver文件。下面以Firefox为例,对geckodriver进行配置。在ubuntu下,将文件下载下来之后解压到指定目录下,我把它解压到firefoxDriver目录下,如图9-12所示。
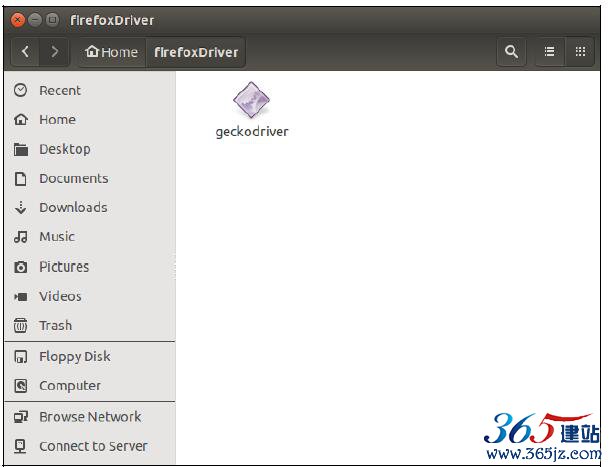
图9-12 补丁解压位置
接着配置环境变量,在shell中执行:export PATH=$PATH:/home/ubuntu/firefoxDr-iver,将geckodriver所在的目录配置到环境变量中,其他操作系统配置方式类似。
9.4.2 Selenium快速入门
安装和配置完成后,现在开始使用Selenium写一个小例子,功能是打开百度主页,在搜索框中输入网络爬虫,进行搜索。代码如下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
assert u"百度" in driver.title
elem = driver.find_element_by_name("wd")
elem.clear()
elem.send_keys(u"网络爬虫")
elem.send_keys(Keys.RETURN)
time.sleep(3)
assert u"网络爬虫." not in driver.page_source
driver.close()
效果如图9-13所示。
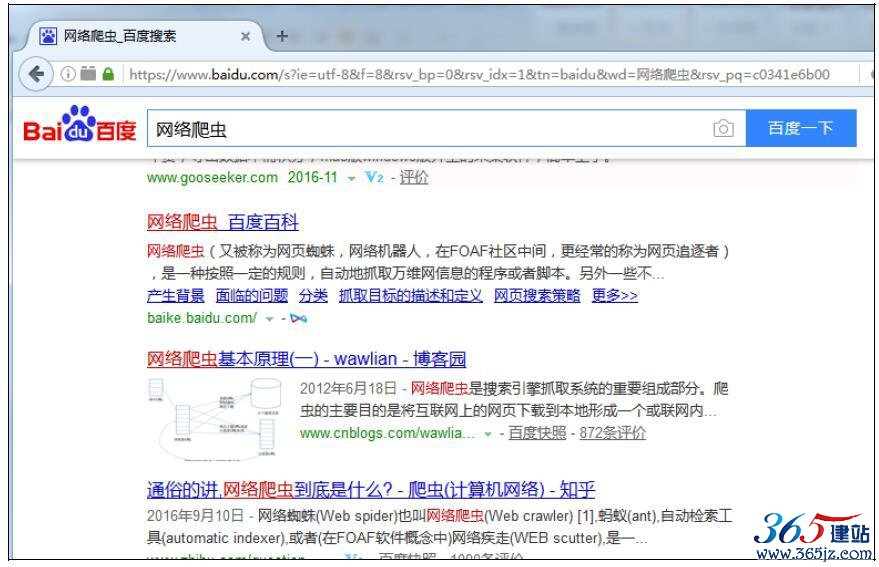
图9-13 搜索网络爬虫
代码分析:首先使用webdriver.Firefox()获取Firefox浏览器的驱动,调用get方法,打开百度首页,判断标题中是否包含百度字样,接着通过元素名称wd获取输入框,通过send_keys方法将网络爬虫填写其中,然后回车。延时3秒后,判断搜索页面是否有网络爬虫字样,最后关闭driver。
我相信即使是同样的代码,大家也会遇到各种各样的问题。下面将大家可能遇到的问题进行一下总结:
1)错误信息为:Exception AttributeError:“’Service‘object has no attribute’process‘”in...,可能是geckodriver环境变量有问题,重新将geckodriver所在目录配置到环境变量中。或者直接在代码中指定路径:
webdriver.Firefox(executable_path=’/home/ubuntu/firefoxDriver/geckodriver)‘
2)错误信息为:selenium.common.exceptions.
WebDriverException:Message:Unsupported Marionette protocol
version 2,required 3,可能是Firefox版本太低,使用Selenium3.x要求Firefox>=v47。
3)错误信息为:selenium.common.exceptions.
WebDriverException:Message:Failed to start browser,可能是没找到Firefox浏览器,可以在代码中指定Firefox的位置:
binary = FirefoxBinary(r'E:\Mozilla Firefox\firefox.exe')
driver = webdriver.Firefox(firefox_binary=binary)
9.4.3 元素选取
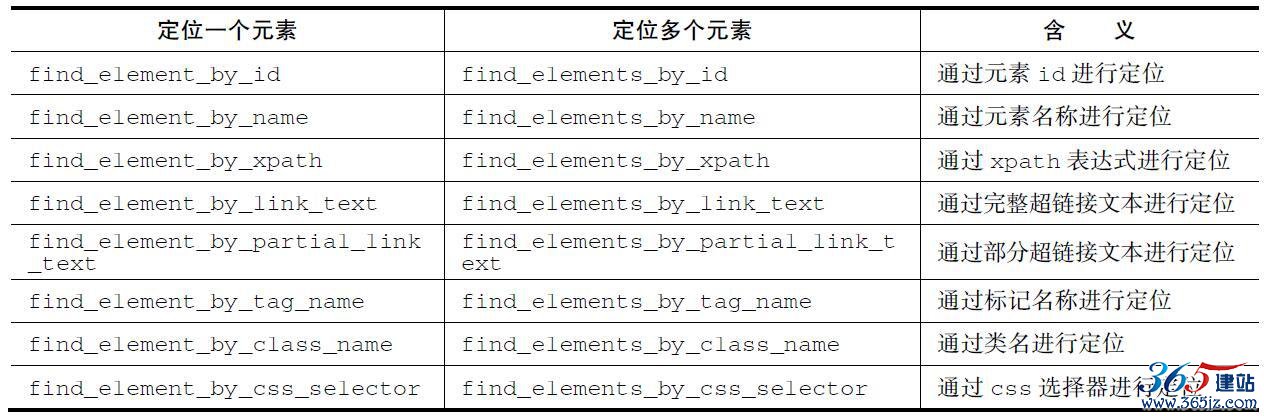
要想对页面进行操作,首先要做的是选中页面元素。元素选取方法如表9-5所示。
表9-5 定位方法
除了上面具有确定功能的方法,还有两个通用方法find_element和find_elements,可以通过传入参数来指定功能。示例如下:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '// button[text()="Some text"]')
这一个例子是通过xpath表达式来查找,方法中第一个参数是指定选取元素的方式,第二个参数是选取元素需要传入的值或表达式。
第一个参数还可以传入By类中的以下值:
·By.ID·By.XPATH·By.LINK_TEXT·By.PARTIAL_LINK_TEXT·By.NAME
·By.TAG_NAME·By.CLASS_NAME·By.CSS_SELECTOR
下面通过一个HTML文档来讲解一下如何使用以上方法提取内容,HTML文档如下:
<html> <body> <h1>Welcome</h1> <p class="content">用户登录</p> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> <a href="register.html">Register</a> </body> <html>
定位方法的使用如表9-6所示。
表9-6 定位方法示例

9.4.4 页面操作
以如下HTML文档为例介绍页面操作,login.html代码如下:
<html> <head> <meta http-equiv="content-type" content="text/html;charset=gbk"> </head> <body> <h1>Welcome</h1> <p class="content">用户登录</p> <form id="loginForm"> <select name="loginways"> <option value="email">邮箱</option> <option value="mobile">手机号</option> <option value="name">用户名</option> </select> <br/> <input name="username" type="text" />
<br/> 密码
<br/> <input name="password" type="password" /> <br/><br/> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> <a href="register.html">Register</a> </body> </html>
效果如图9-14所示。
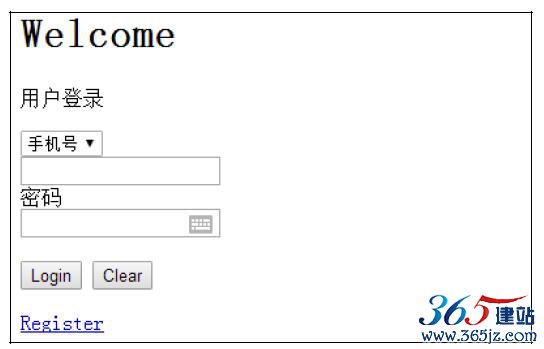
图9-14 登录页面
1.页面交互与填充表单
第一步:初始化Firefox驱动,打开html文件,由于是本地文件,可以使用下面方式打开。
driver = webdriver.Firefox()
driver.get("file:// /e:/login.html")
第二步:获取用户名和密码的输入框,和登录按钮。
username = driver.find_element_by_name('username')
password = driver.find_element_by_xpath(".// *[@id='loginForm']/input[2]")
login_button = driver.find_element_by_xpath("// input[@type='submit']")
第三步:使用send_keys方法输入用户名和密码,使用click方法模拟点击登录。
username.send_keys("qiye")
password.send_keys("qiye_pass")
login_button.click()
如果想清除username和password输入框的内容,可以使用clear方法。
username.clear()
password.clear()
上面还有一个问题没解决,如何操作下拉选项卡选择登录方式呢?第一种方法代码如下:
select = driver.find_element_by_xpath("// form/select")
all_options = select.find_elements_by_tag_name("option")
for option in all_options:
print("Value is: %s" % option.get_attribute("value"))
option.click()
在代码中首先获取select元素,也就是下拉选项卡。然后轮流设置了select选项卡中的每一个option选项。这并不是一个非常好的办法。官方提供了更好的实现方式,在WebDriver中提供了一个叫
Select方法,也就是第二种操作方式。代码如下:
from selenium.webdriver.support.ui import Select
select = Select(driver.find_element_by_xpath('// form/select '))
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)
它可以根据索引、文字、value值来选择选项卡中的某一项。
如果select标记中multiple=“multiple”,也就是说这个select标记支持多选,Select对象提供了支持此功能的方法和属性。示例如下:
·取消所有的选项:select.deselect_all()
·获取所有的选项:select.options·获取已选中的选项:select.all_selected_options
2.元素拖拽
元素的拖拽即将一个元素拖到另一个元素的位置,类似于拼图。
首先要找到源元素和目的元素,然后使用ActionChains类可以实现。
代码如下:
element = driver.find_element_by_name("source")
target = driver.find_element_by_name("target")
from selenium.webdriver import ActionChains
action_chains = ActionChains(driver)
action_chains.drag_and_drop(element, target).perform()
3.窗口和页面frame的切换
一个浏览器一般都会开多个窗口,我们可以switch_to_window方法实现指定窗口的切换。示例如下:
driver.switch_to_window("windowName")
也可以通过window handle来获取每个窗口的操作对象。示例如下:
for handle in driver.window_handles:
driver.switch_to_window(handle)
如需切换页面frame,可以使用switch_to_frame方法,示例如下:
driver.switch_to_frame("frameName")
driver.switch_to_frame("frameName.0.child")
4.弹窗处理
如果你在处理页面的过程中,触发了某个事件,跳出弹框。可以使用switch_to_alert获取弹框对象,从而进行关闭弹框、获取弹框信息等操作。示例如下:
alert = driver.switch_to_alert()
alert.dismiss()
5.历史记录
操作页面的前进和后退功能,示例如下:
driver.forward()
driver.back()
6.Cookie处理
可以使用get_cookies方法获取cookie,也可以使用add_cookie方法添加cookie信息。示例如下:
driver.get("http://www.baidu.com")
cookie = {'name': 'foo', 'value' : 'bar'} driver.add_cookie(cookie)
driver.get_cookies()
7.设置phantomJS请求头中User-Agent
这个功能在爬虫中非常有用,一般针对phantomJS的反爬虫措施都会检测这个字段,默认的User-Agent中含有phantomJS内容,可以通过代码进行修改。代码如下:
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ( "Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.
36 (KHTML, like Gecko) Chrome/48.0.2564.23 Mobile Safari/537.36"
)
driver = webdriver.PhantomJS()# desired_capabilities=dcap)
driver.get("http://www.google.com")
driver.quit()
9.4.5 等待
由于现在很多网站采用Ajax技术,不确定网页元素什么时候能被完全加载,所以网页元素的选取会比较困难,这时候就需要等待。
Selenium有两种等待方式,一种是显式等待,一种是隐式等待。
1.显式等待
显式等待是一种条件触发式的等待方式,指定某一条件直到这个条件成立时才会继续执行,可以设置超时时间,如果超过这个时间元素依然没被加载,就会抛出异常。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
以上代码加载http://somedomain/url_that_delays_loading页面,并定位id为myDynamic Element的元素,设置超时时间为10s。
WebDriverWait默认会500ms检测一下元素是否存在。
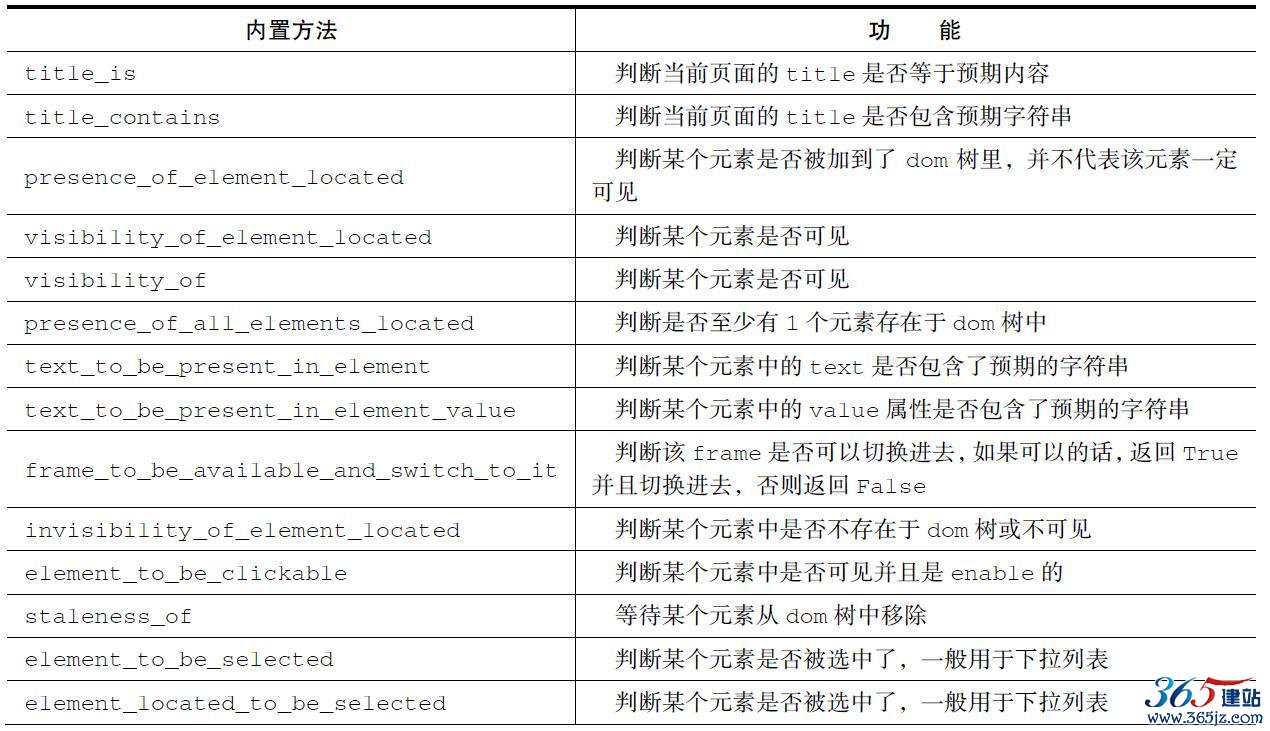
Selenium提供了一些内置的用于显式等待的方法,位于
expected_conditions类中,方法名称如表9-7所示:
表9-7 内置方法

2.隐式等待
隐式等待是在尝试发现某个元素的时候,如果没能立刻发现,就等待固定长度的时间,类似于socket超时,默认设置是0秒。一旦设置了隐式等待时间,它的作用范围是Webdriver对象实例的整个生命周期,也就是说Webdriver执行每条命令的超时时间都是如此。如果大家感觉设置的时间过长,可以进行不断地修改。使用方法示例如下:
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # seconds
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
3.线程休眠
time.sleep(time),这是使用线程休眠延时的办法,也是比较常用的。
如对本文有疑问,请提交到交流论坛,广大热心网友会为你解答!! 点击进入论坛
- 上一篇:建站之制作自己的视频网站实例
- 下一篇:建站之制作自己的电子商务网站的实例教程

